[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]  Jeff Davies, the Energy OG [@EnergyCredit1](/creator/twitter/EnergyCredit1) on x 37.7K followers Created: 2025-07-18 19:15:29 UTC Lot of debate on $NBIS vs $IREN and the value of a software stack. The blog below helps articulate why $NBIS is different than every other neocloud. - They have their own LLM team, run by Boris Yangel, who has a long track record of being ML/AI expert. He is the type of dude that could walk from $NBIS and get the $100mil checks at META. Some of his collaborators on papers are AI researchers as MSFT. - This is the hyperscaler model, build products that work internally then roll out externally - No other neocloud has their own LLM team - No other neocloud has the full stack domain expertise - No other neocloud was previously a hyperscaler The AI R&D team also acts as an early adopter of all our in-house developed hardware technologies. For example, our ML engineers are the first to test new types of nodes for model training (based on SXM5) and inference (PCIe-based). Another example is the introduction of new InfiniBand fabrics — each new fabric initially hosts the AI R&D team. We see this as a significant competitive advantage, especially when rolling out major features. It lies in the fact that these features are tested by very strong domain experts. They can not only point out that something is not working but also dig much deeper to answer why it is not working. The AI R&D team is capable of investigating issues down to tracing processes within Linux, understanding why their code stumbles upon these processes. This is where the cloud architects' responsibility comes back in, finding ways to get more out of our systems. We hope we’ve conveyed the importance of this symbiotic relationship. The AI R&D team was the first client of Nebius, even before external clients were connected. Among other things, the input of the team helped bring cluster characteristics to the levels now applicable to all users. Later, ML engineers assisted the whole GPU development team (consisting of many teams across Nebius) in optimizing network loads in our data center. They also helped optimize checkpointing, job scheduling and cluster scaling (network, scaling and storage are usually the bottlenecks when building large clusters for model training). Our ML engineers acted as the first 'filter' — their feedback allowed us to identify and address these and other weak points before the public launch of the platform. There’s a gap between ML engineers and the infrastructure they can get from the market. We’re closing such a gap by bringing together three pieces: hardware, software and ML proficiency. Our extensive background in designing servers, racks and the whole DC structure led, for instance, to the construction the world’s #16 supercomputer (as of Nov 2023 — we multiplied our capacity x5 since then). After that, the decision to build a 10K GPU cluster, a scalable infrastructure of 10,000+ cards, was a natural one. Nebius software enables us to provide orchestrated machines on top of that, with diverse tools enhancing the setup. But then there’s the third piece, ML expertise. To build a full-fledged ML platform — an end-to-end management solution for the entire ML workflow — we realized it’s necessary to perform large-scale distributed training in-house. What else would enable us to practically understand ML engineers’ needs? That’s why we formed the AI R&D team, leveraging our compute capacities to let us deeply specialize the platform, while also advancing our own AI efforts. The team is led by Boris Yangel, a research engineer with more than a decade of experience leading complex AI projects, from neural world models for self-driving cars to text generation and understanding for AI assistants. 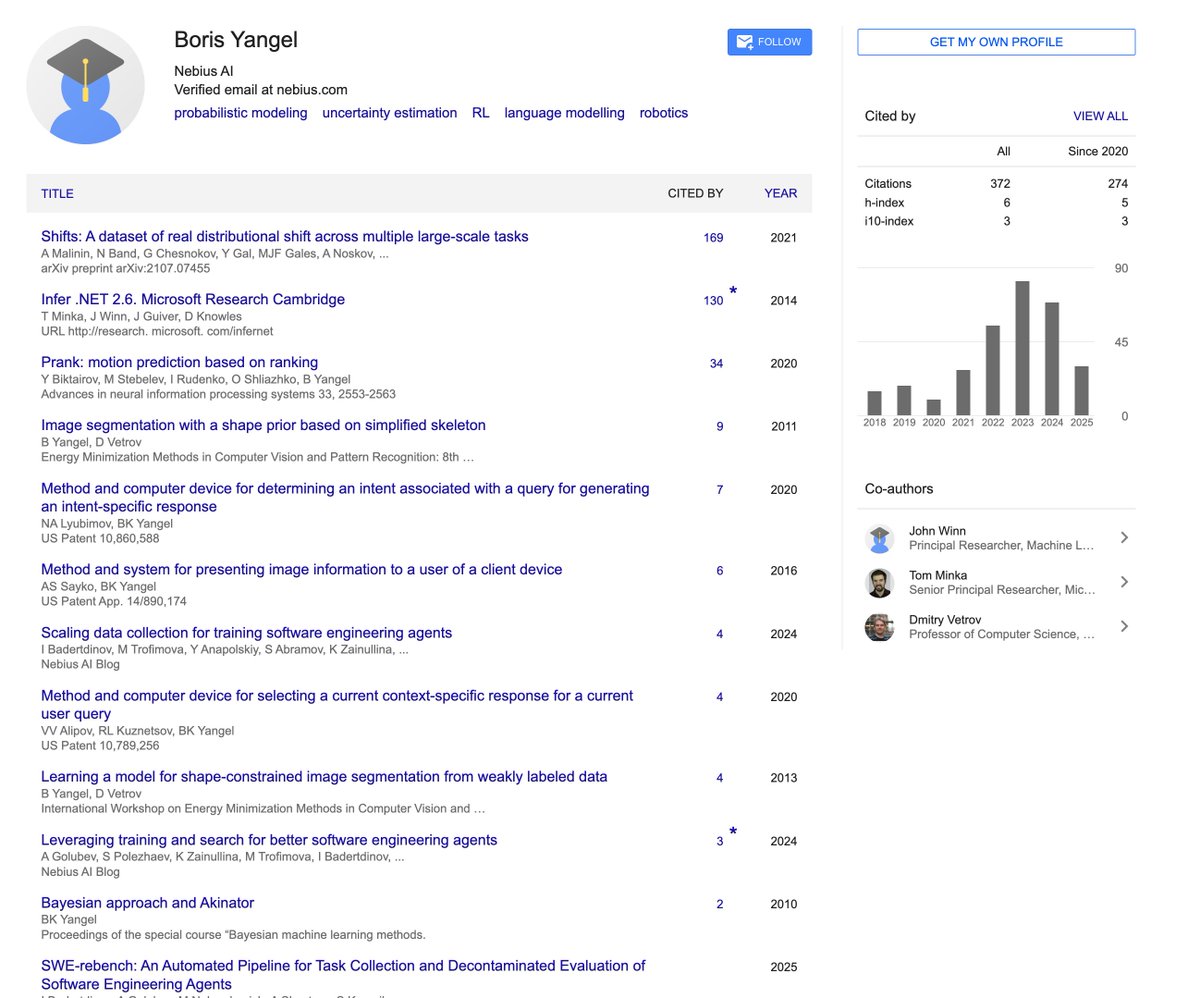 XXXXX engagements  **Related Topics** [loop](/topic/loop) [coins ai](/topic/coins-ai) [meta](/topic/meta) [$100mil](/topic/$100mil) [llm](/topic/llm) [blog](/topic/blog) [og](/topic/og) [coins energy](/topic/coins-energy) [Post Link](https://x.com/EnergyCredit1/status/1946287729891033290)
[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]
 Jeff Davies, the Energy OG @EnergyCredit1 on x 37.7K followers
Created: 2025-07-18 19:15:29 UTC
Jeff Davies, the Energy OG @EnergyCredit1 on x 37.7K followers
Created: 2025-07-18 19:15:29 UTC
Lot of debate on $NBIS vs $IREN and the value of a software stack. The blog below helps articulate why $NBIS is different than every other neocloud.
- They have their own LLM team, run by Boris Yangel, who has a long track record of being ML/AI expert. He is the type of dude that could walk from $NBIS and get the $100mil checks at META. Some of his collaborators on papers are AI researchers as MSFT.
- This is the hyperscaler model, build products that work internally then roll out externally
- No other neocloud has their own LLM team
- No other neocloud has the full stack domain expertise
- No other neocloud was previously a hyperscaler
The AI R&D team also acts as an early adopter of all our in-house developed hardware technologies. For example, our ML engineers are the first to test new types of nodes for model training (based on SXM5) and inference (PCIe-based). Another example is the introduction of new InfiniBand fabrics — each new fabric initially hosts the AI R&D team.
We see this as a significant competitive advantage, especially when rolling out major features. It lies in the fact that these features are tested by very strong domain experts. They can not only point out that something is not working but also dig much deeper to answer why it is not working. The AI R&D team is capable of investigating issues down to tracing processes within Linux, understanding why their code stumbles upon these processes. This is where the cloud architects' responsibility comes back in, finding ways to get more out of our systems. We hope we’ve conveyed the importance of this symbiotic relationship.
The AI R&D team was the first client of Nebius, even before external clients were connected. Among other things, the input of the team helped bring cluster characteristics to the levels now applicable to all users. Later, ML engineers assisted the whole GPU development team (consisting of many teams across Nebius) in optimizing network loads in our data center. They also helped optimize checkpointing, job scheduling and cluster scaling (network, scaling and storage are usually the bottlenecks when building large clusters for model training). Our ML engineers acted as the first 'filter' — their feedback allowed us to identify and address these and other weak points before the public launch of the platform.
There’s a gap between ML engineers and the infrastructure they can get from the market. We’re closing such a gap by bringing together three pieces: hardware, software and ML proficiency. Our extensive background in designing servers, racks and the whole DC structure led, for instance, to the construction the world’s #16 supercomputer (as of Nov 2023 — we multiplied our capacity x5 since then). After that, the decision to build a 10K GPU cluster, a scalable infrastructure of 10,000+ cards, was a natural one. Nebius software enables us to provide orchestrated machines on top of that, with diverse tools enhancing the setup.
But then there’s the third piece, ML expertise. To build a full-fledged ML platform — an end-to-end management solution for the entire ML workflow — we realized it’s necessary to perform large-scale distributed training in-house. What else would enable us to practically understand ML engineers’ needs? That’s why we formed the AI R&D team, leveraging our compute capacities to let us deeply specialize the platform, while also advancing our own AI efforts. The team is led by Boris Yangel, a research engineer with more than a decade of experience leading complex AI projects, from neural world models for self-driving cars to text generation and understanding for AI assistants.

XXXXX engagements

Related Topics loop coins ai meta $100mil llm blog og coins energy