[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]  Rohan Paul [@rohanpaul_ai](/creator/twitter/rohanpaul_ai) on x 73.7K followers Created: 2025-07-17 18:29:45 UTC 🖥️ OpenAI rolled out “agent mode,” in ChatGPT. Lets the model click around a virtual computer, run code, and finish multistep jobs on its own, hitting XXXX% on Humanity’s Last Exam while handling chores like building slide decks or buying groceries. It reaches XXXX% accuracy on Humanity’s Last Exam (HLE), while older baselines like OpenAI o3 without tools sit at XXXX% and deep-research with browsing reaches 26.6%. The HLE exam spans XXXXX expert-level questions across 100+ subjects that were crowdsourced specifically to stump modern language models. So coubling the previous best pass@1 score signals a jump in broad reasoning skill, not just memorization. The leap comes from giving the model its own virtual computer with a browser, terminal, and API hooks so it can fetch data, run code, and decide which tool to use on the fly. OpenAI also says that the agent ran up to X attempts in parallel and picked the answer the model felt most confident about, got the score pushed to XXXX% So overall, agents that can act as well as reason are starting to close the gap with human experts. 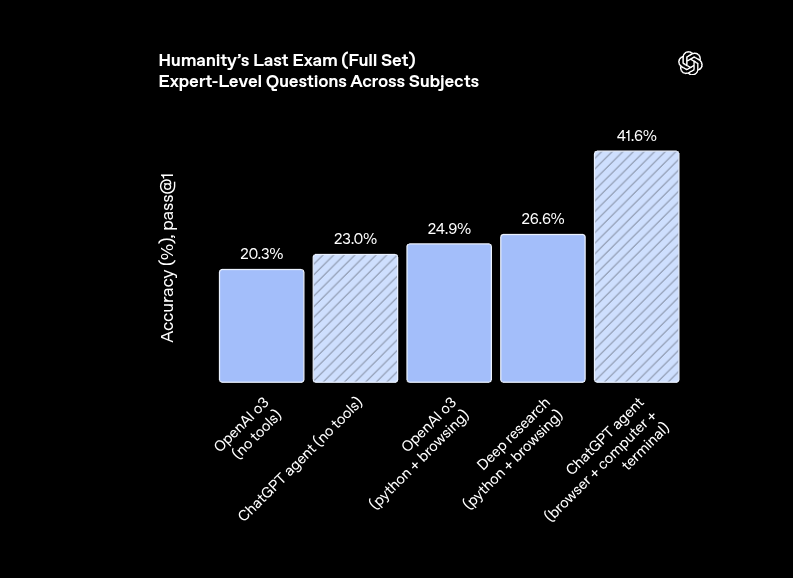 XXXXX engagements  **Related Topics** [groceries](/topic/groceries) [virtual](/topic/virtual) [open ai](/topic/open-ai) [Post Link](https://x.com/rohanpaul_ai/status/1945913831370453072)
[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]
 Rohan Paul @rohanpaul_ai on x 73.7K followers
Created: 2025-07-17 18:29:45 UTC
Rohan Paul @rohanpaul_ai on x 73.7K followers
Created: 2025-07-17 18:29:45 UTC
🖥️ OpenAI rolled out “agent mode,” in ChatGPT.
Lets the model click around a virtual computer, run code, and finish multistep jobs on its own, hitting XXXX% on Humanity’s Last Exam while handling chores like building slide decks or buying groceries.
It reaches XXXX% accuracy on Humanity’s Last Exam (HLE), while older baselines like OpenAI o3 without tools sit at XXXX% and deep-research with browsing reaches 26.6%.
The HLE exam spans XXXXX expert-level questions across 100+ subjects that were crowdsourced specifically to stump modern language models.
So coubling the previous best pass@1 score signals a jump in broad reasoning skill, not just memorization.
The leap comes from giving the model its own virtual computer with a browser, terminal, and API hooks so it can fetch data, run code, and decide which tool to use on the fly.
OpenAI also says that the agent ran up to X attempts in parallel and picked the answer the model felt most confident about, got the score pushed to XXXX%
So overall, agents that can act as well as reason are starting to close the gap with human experts.

XXXXX engagements
