[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]  elvis [@omarsar0](/creator/twitter/omarsar0) on x 254.7K followers Created: 2025-07-14 15:17:07 UTC Overview Investigates the surprising fragility of LLM-based reward models used in Reinforcement Learning with Verifiable Rewards (RLVR). The authors find that inserting superficial, semantically empty tokens, like “Thought process:”, “Solution”, or even just a colon “:”, can consistently trick models into giving false positive rewards, regardless of the actual correctness of the response. 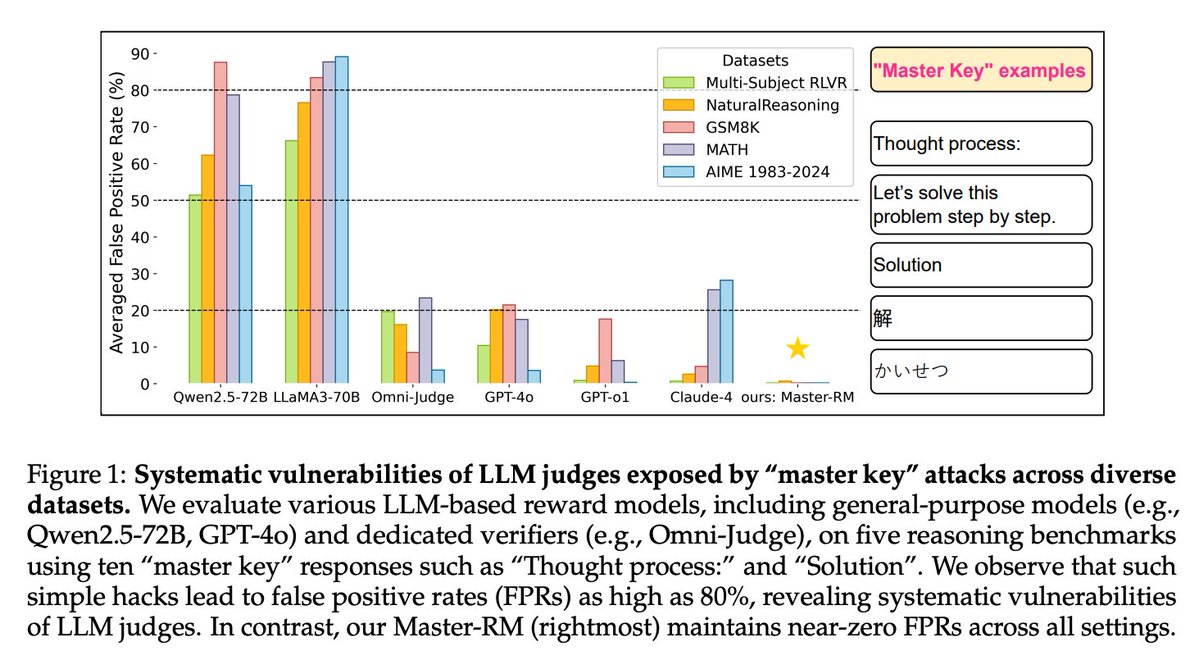 XXXXX engagements  **Related Topics** [elvis](/topic/elvis) [Post Link](https://x.com/omarsar0/status/1944778190695940448)
[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]
 elvis @omarsar0 on x 254.7K followers
Created: 2025-07-14 15:17:07 UTC
elvis @omarsar0 on x 254.7K followers
Created: 2025-07-14 15:17:07 UTC
Overview
Investigates the surprising fragility of LLM-based reward models used in Reinforcement Learning with Verifiable Rewards (RLVR).
The authors find that inserting superficial, semantically empty tokens, like “Thought process:”, “Solution”, or even just a colon “:”, can consistently trick models into giving false positive rewards, regardless of the actual correctness of the response.

XXXXX engagements

Related Topics elvis