[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]  Andrej Karpathy [@karpathy](/creator/twitter/karpathy) on x 1.4M followers Created: 2025-01-30 18:03:21 UTC We have to take the LLMs to school. When you open any textbook, you'll see three major types of information: X. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge. X. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans. X. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning. We've subjected LLMs to a ton of X and 2, but X is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these X types of data. They have to read, and they have to practice. 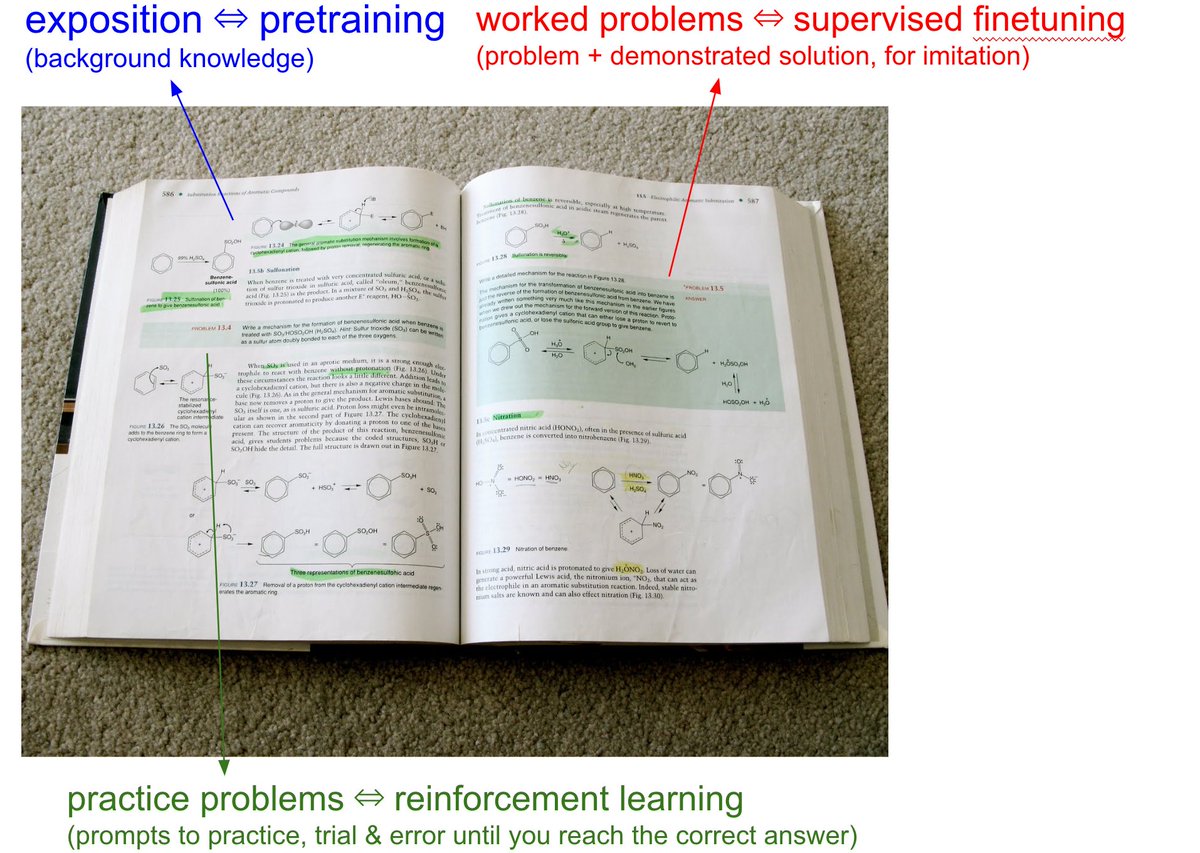 XXXXXXX engagements  [Post Link](https://x.com/karpathy/status/1885026028428681698)
[GUEST ACCESS MODE: Data is scrambled or limited to provide examples. Make requests using your API key to unlock full data. Check https://lunarcrush.ai/auth for authentication information.]
 Andrej Karpathy @karpathy on x 1.4M followers
Created: 2025-01-30 18:03:21 UTC
Andrej Karpathy @karpathy on x 1.4M followers
Created: 2025-01-30 18:03:21 UTC
We have to take the LLMs to school.
When you open any textbook, you'll see three major types of information:
X. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge.
X. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans.
X. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning.
We've subjected LLMs to a ton of X and 2, but X is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these X types of data. They have to read, and they have to practice.

XXXXXXX engagements
